Si hay algo que genera actualmente «morbo» es precisamente la nueva arquitectura de Intel para GPUs y sobre todo, qué nos deparará el gigante azul para competir con NVIDIA y AMD (si puede llegar a ese nivel nada más llegar). Ha sido en el HotChip 2020 donde David Blythe ya hablado más en profundidad sobre lo que como jefe de arquitectura de GPU de la compañía podemos esperar para el año que viene. Y a decir verdad, la espera para Intel Xe se nos va a hacer larga …
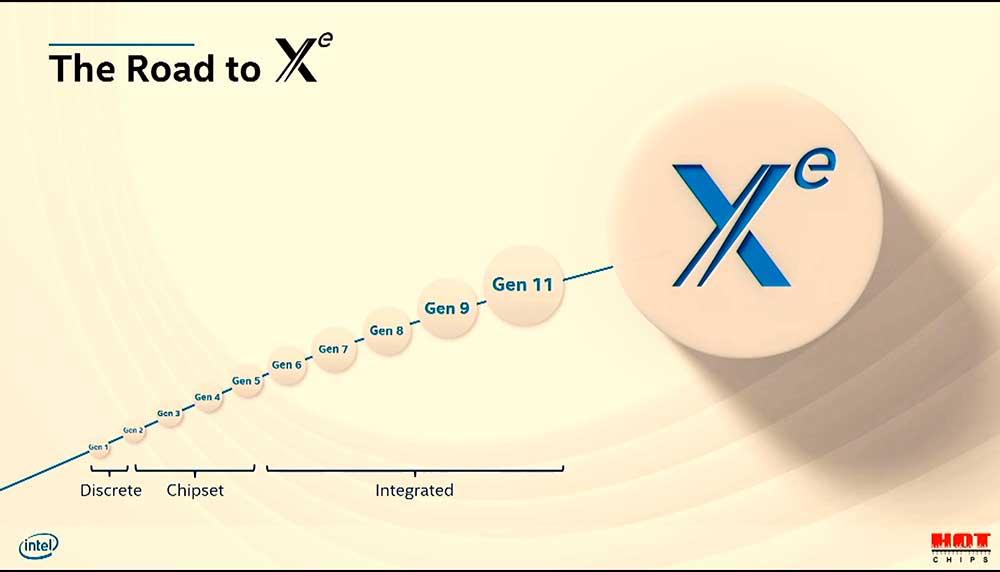
En primer lugar, Blythe ha dejado claro que Gen 11 será la última arquitectura denominada de tal forma y que a partir de ahora todo se basará en Xe como arquitectura modular, escalable y central de la compañía. Los puntos clave se dividen en tres apartados básicos: escalabilidad y configurabilidad, nuevas capacidades y por último, energía, rendimiento y área a tratar.
Intel Xe: una arquitectura para cuatro micro arquitecturas

La ponencia virtual ha dejado claro que Intel ha tenido que trabajar muy duro, ya que asegura que el diseño es completamente nuevo frente a lo visto en Gen 11, algo que ya comentamos en artículos anteriores tras su presentación en el Intel Architecture Day correspondiente.

Los niveles serán los ya sabidos LP, HPG, HP y HPC, todos optimizados para diferentes requisitos del mercado. Tanto es así, que la compañía afirma estar optimizando cada segmento con requisitos individuales para potenciar sus productos de forma unitaria y poder competir contra sus rivales de tú a tú.
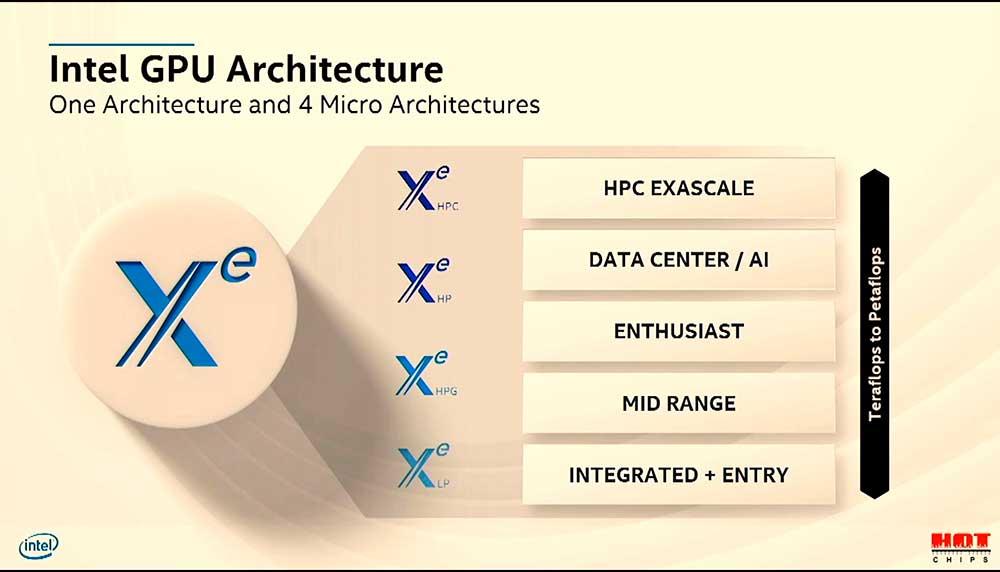
Por lo tanto, se asume que LP representará la gama baja e integrados, HPG rango medio y entusiasta para gaming, HP irá enfocado a centros de datos e inteligencia artificial y HPC es el rango de exaescala para grandes ordenadores exoescalables.
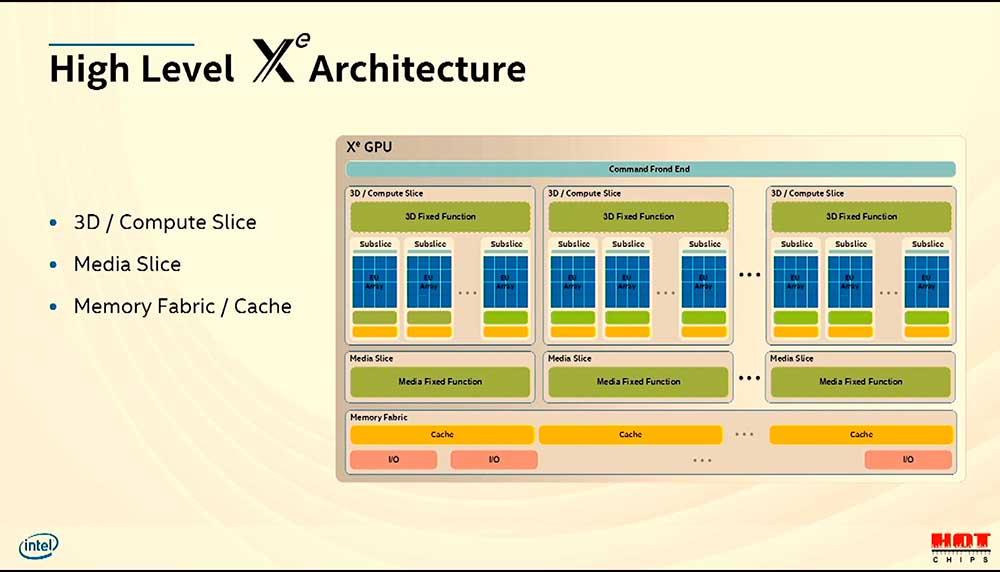
Entrando un poco más en la arquitectura en sí, Intel dividirá sus unidades mínimas en los llamados 3D Compute Slice, Media Slice y Memory Fabric, donde estos tres apartados tendrán diferentes tipos de unidades. Desde funciones 3D hasta media o cachés con I/O.
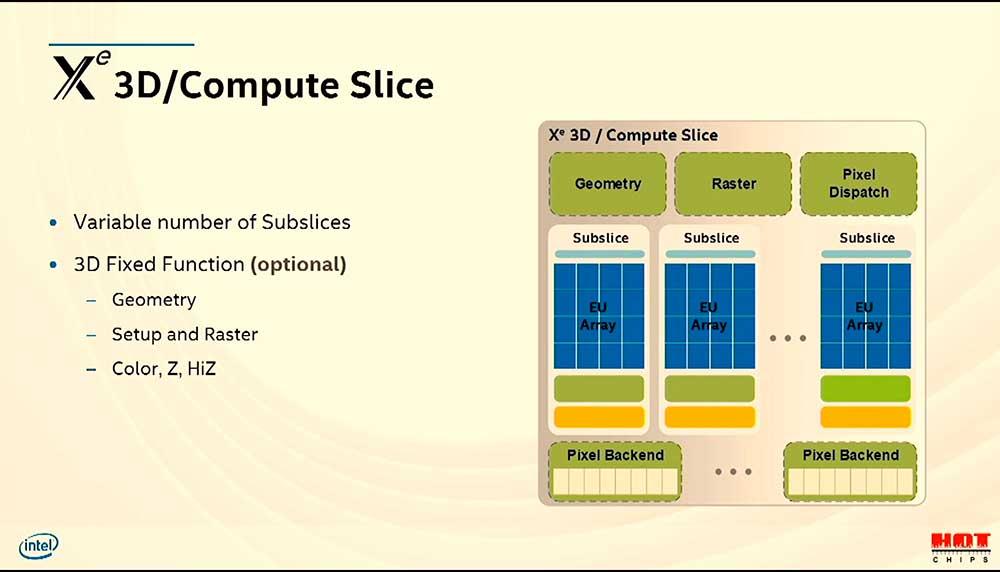
Cada segmento por lo tanto tiene sus correspondientes subsegmentos, donde Intel ha querido profundizar en el más importante, el 3D Compute Slice. Este tendrá dentro de las funciones un motor de geometría, raster y Dispatch (Color, Z y HiZ según la compañía).
Los SubSlice son opcionales y ajustables según el producto a diseñar, así que partiendo de la base de que cada Compute Slice contiene 16 EUs, los chips serán múltiplos de este número.
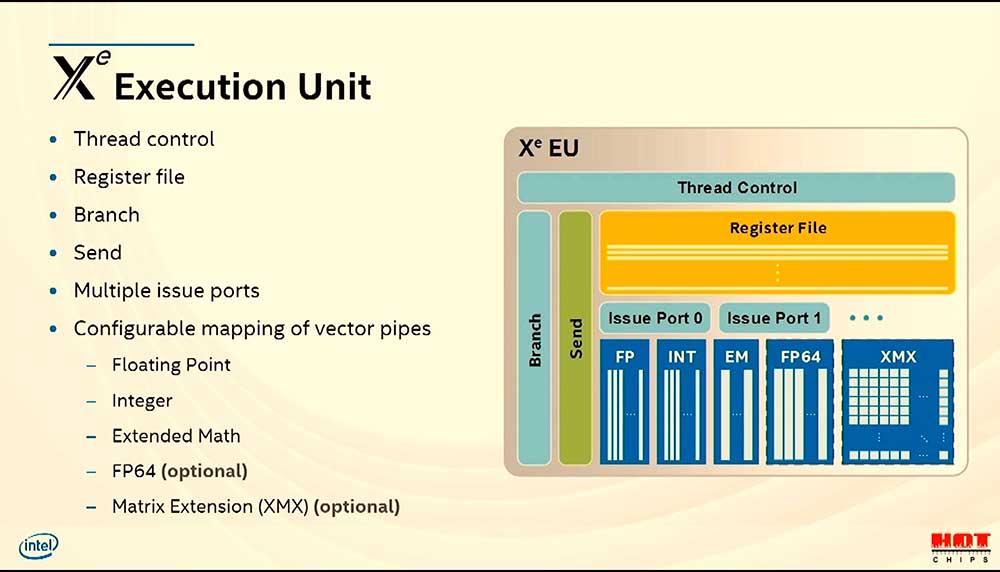
Así mismo, cada SubSlice tendrá un Thread Dispatch, instrucciones de caché, L1, texturas y memoria compartida de forma local, unidades de carga y descarga y las llamadas Fixed funcion que son opcionales en tres unidades: 3D Sampler, Media Sampler y Ray Tracing.
Una unidad de Ray Tracing por cada 16 EUs, ¿por qué esta disposición?
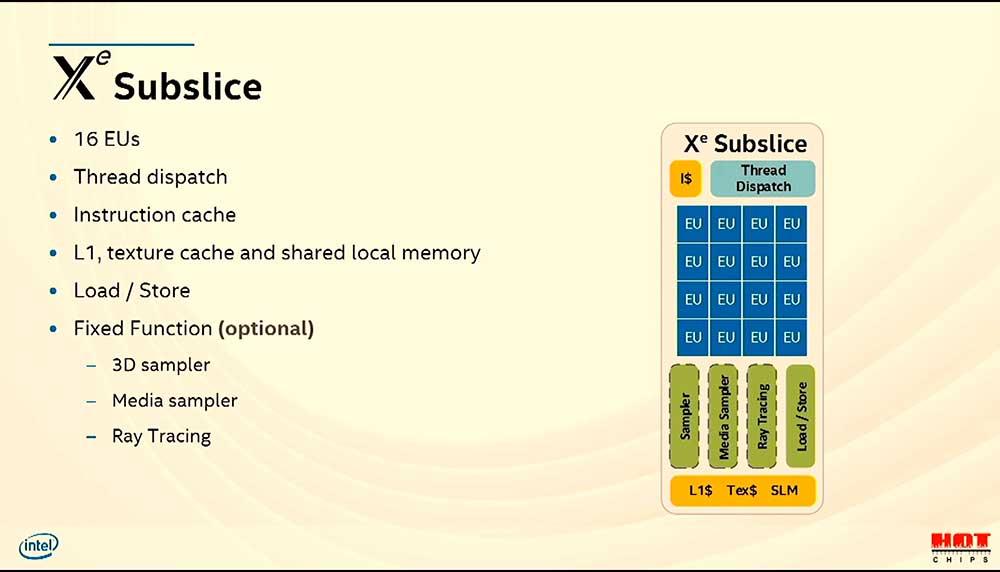
Si tenemos en cuenta que cada 16 EUs de un Subslice van acompañadas de 128 líneas SIMD, el hecho de incluir una unidad para trabajar con Ray Tracing por cada uno de dichos Subslice solo se puede entender desde el punto de vista de la eficiencia.
Blythe fue preguntado sobre esto y aseguró que es la escalabilidad adecuada para la arquitectura, y además dejó otra perla: el rendimiento de Ray Tracing puede ser modulado también, ya que no es solamente una unidad de tamaño fijo. Esto deja abierta la puerta a posibles chips con mejor rendimiento en Ray Tracing según las necesidades del mismo.
Volviendo a los EU como tal, Intel aseguró que tendrán 8 puertos INT/FP con dos complex math, donde destacan el soporte para FP64 y sobre todo las extensión XMX, ambas opcionales y que solo se incluirán en HP y HPC a petición del comprador muy posiblemente.
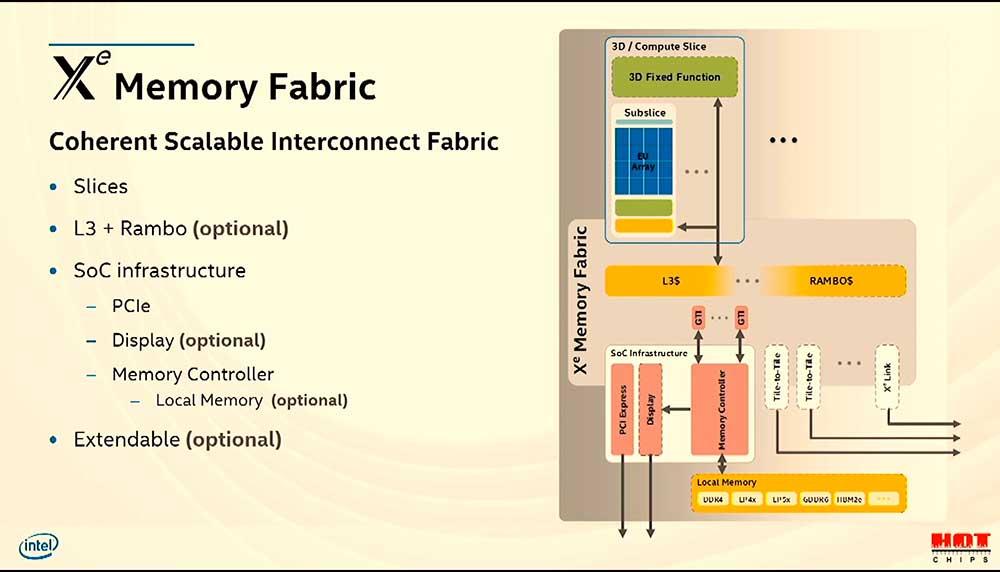
El siguiente punto interesante ha sido sin duda el conocer más de cerca el Memory Fabric. No en vano Intel tiene grandes esperanzas en cuanto a conectar múltiples dies con CXL en el futuro más inmediato. La estructura dibuja una L3 compartida y conectada con la Rambo Caché (sí, se le ha denominado así) ya que esta última es la encargada de conectar CPU, GPU y HBM cuando se precie, así que es muy específica.


Esto es importante desde el punto de vista de la escalabilidad. Y es que Intel Xe está pensada como Tiles y Multi Tiles, no como GPUs unitarias como tal. El sistema Multi Tiles llegará de la mano de EMIB y sus puentes de interconexión (ODI en un futuro suponemos), donde en este caso podremos ver hasta 4 Tiles completas en un mismo encapsulado y en el futuro el número aumentará exponencialmente mediante Xe Link y Co-EMIB.
Intel Tiger Lake, el primer golpe de la compañía
Los azules están dando rienda suelta a los datos facilitados para Tiger Lake, no en vano es el primer chip que integrará la arquitectura Intel Xe y como tal, todas las miradas están puestas en él. Intel afirma que el rendimiento se duplicará literalmente frente a Gen 11, donde además tendrá un área 1,5 veces mayor debido a los motores implementados y a sus 96 EU, que lograrán 1536 operaciones de 32 bits por clock.


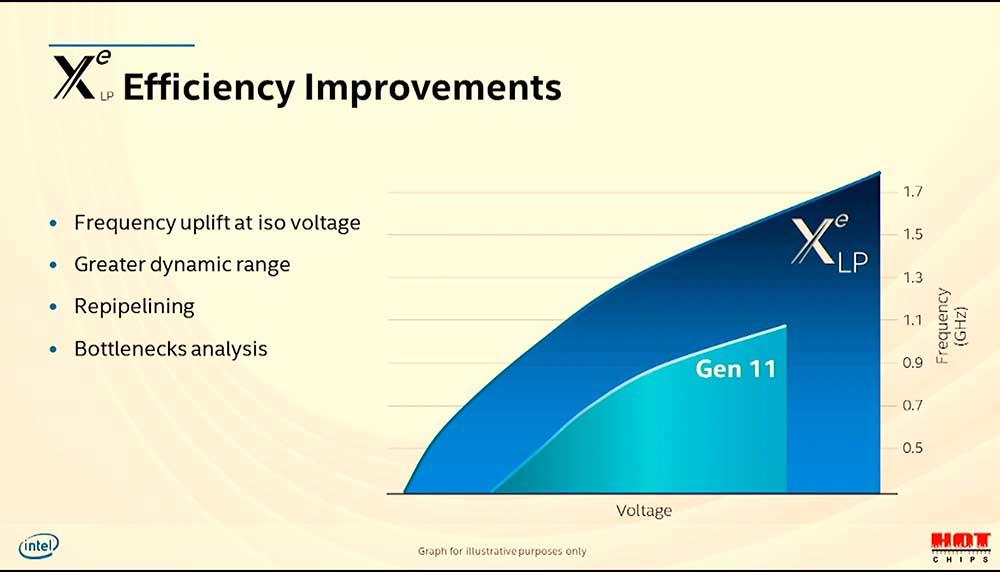
Otro dato importante es que la frecuencia da un salto exponencial de 1,5 veces, donde al parecer estaremos entre los 1,7 GHz y 1,8 GHz aproximadamente, casi al nivel de las tarjetas gráficas dedicadas de AMD y NVIDIA, salvo que Tiger Lake es una iGPU. Por si fuese poco el rango dinámico se ha mejorado, lo que debería incidir en consumos de energía más óptimos.
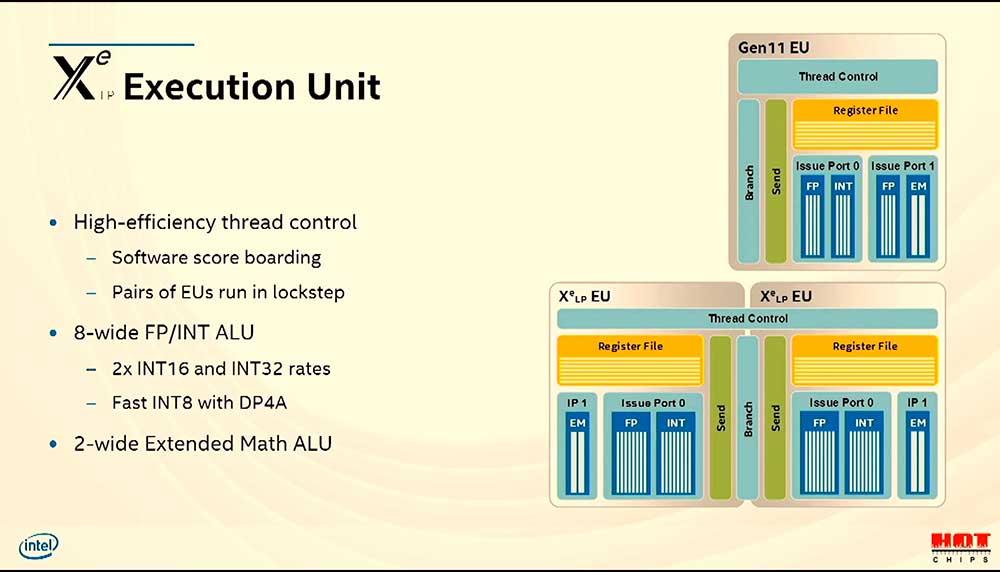
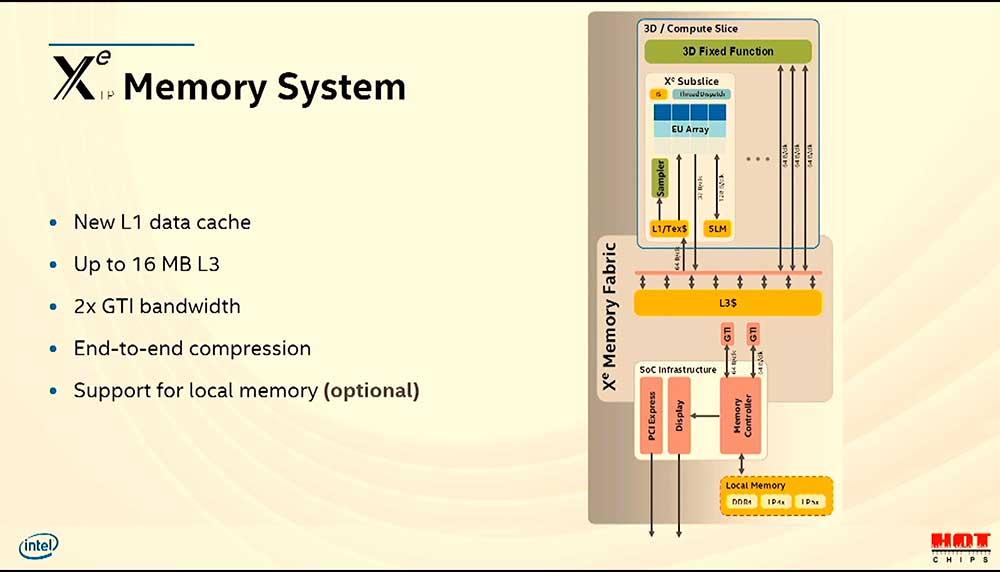
Esto viene en parte por el hecho de cómo van a funcionar los EU y el controlo de los hilos que tendrán. Cada par de EUs que tenga el chip se ejecutarán al mismo tiempo debido a que comparten el control de los subprocesos. Tendrán a su disposición 2 x INT16 e INT32, producto de los 8 FP/INT por cada ALU, algo que agradecerá debido a que cada Subslice tiene su propia L1 y hasta 16 MB de L3.
Intel Xe: golpe en la mesa al soportar AV1 y duplicar el rendimiento en codificación/descodificación

Si algo valoran cada vez más usuarios es el rendimiento en el llamado Media Performance. En este aspecto Intel ha dado un salto cualitativo al soportar decodificación de AV1 de serie, HEVC screen content coding, reproducción 4K y 8K a 60 FPS, HDR y Dolby Vision y un pipeline para vídeo de 12 bits.

Para finalizar, David dio datos concretos sobre el rendimiento el GFLOP y bajo FP32 para que el público se hiciese una idea de lo que puede esperar:
- 1 Tile -> 10,6 GFLOP.
- 2 Tile -> 21161 GFLOP.
- 4 Tile -> 42K GFLOP.
Esto deja claro el por qué Intel va a tener que externalizar su producción para sus GPU gaming a TSMC: necesitan un proceso muy avanzado y ya con EUV para lograr un rendimiento similar a lo que se espera de sus rivales directos por el mercado de videojuegos.

Los 6 nm de TSMC ya llegan con un menor número de capas en EUV y son solamente una versión mejorada de los 7 nm EUV de la compañía, por lo que el diseño y patrones no debería cambiar mucho y aunque Intel no tenga experiencia con TSMC, sí puede ver lo que han hecho AMD y NVIDIA en cada troquel, por lo que no debería ser demasiado difícil incluir máscaras para el proceso de grabado de los taiwaneses.
En cualquier caso, 2021 se presenta apasionante y aunque los azules llegarán los últimos a la lucha, no descartemos que puedan dar la sorpresa en rendimiento/precio con Intel Xe gracias precisamente a la externalización y precios competitivos que ofrecerá TSMC.
Fuente: hardzone.es/marcas/intel/intel-xe-arquitectura-caracteristicas/