
Los procesadores se basan en tres métricas para medir su rendimiento distintas: el área que ocupan, la velocidad que alcanzan a la hora ejecutar instrucciones y el consumo energético. Dos de estos parámetros, consumo y área, son limitaciones al diseño de cualquier procesador que se precie incluida una GPU, especialmente en cuanto al consumo, ya que no es lo mismo diseñar para un dispositivo que consume 5 W que uno que consume 100 W, lo que lleva a diseños diferentes. En esta entrada os vamos a hablar del rendimiento por vatio, el cual mide la potencia de un procesador bajo un consumo energético concreto.
Sería ideal que una misma arquitectura gráfica fuese escalable desde el smartphone más simple hasta la estación de trabajo más avanzada, pero desgraciadamente no ocurre de esta manera.
Arquitecturas gráficas para smartphones como PowerVR, Mali, Adreno y otras muchas. No escalan de manera progresiva en rendimiento y se llega al punto en que pierden su eficiencia energética si las hacemos escalar hacía arriba con el objetivo de colocarlas en un PC. Por otro lado, las GPUs de PC como las GeForce de NVIDIA y las Radeon de AMD escalan muy mal hacía abajo y no son viables en dispositivos de menor consumo que un PC convencional como son los dispositivos PostPC.
Si alguna vez os habéis preguntado el motivo por el cuál no vemos una Radeon en un smartphone o una PowerVR en PC gaming de alta gama, esperamos que después de leer este artículo tengáis al menos la mayor parte de esa duda respondida.
Rendimiento por vatio o como hacer más con menos energía

El rendimiento por vatio es utilizado como métrica en toda arquitectura informática para hablar de la eficiencia energética de la misma, es decir, su capacidad de cálculo bajo un consumo de energía dado. Se consigue con una simple división entre la potencia obtenida y el consumo en ese mismo momento.Si queremos comparar dos GPUs solo tenemos que asegurarnos que ambas consumen la misma cantidad de energía, es decir, los mismos vatios y comparar ambas ejecutando el mismo programa.
El rendimiento por vatio es a día de hoy la mayor obsesión de los arquitectos a la hora de diseñar hardware nuevo, el motivo no es otro que poder alcanzar la potencia esperada con un consumo energético menor, lo que tiene una serie de consecuencias positivas, entre las que destacan:
- Se pueden plantear vender una versión del chip mucho más rápida de lo que habían planteado inicialmente, esto supondrá una ventaja comercial frente a la competencia.
- Es más fácil alcanzar la velocidad objetivo en los test posteriores a la fabricación.
- Permite alcanzar factores forma más allá de los habituales, el mayor rendimiento por vatio de NVIDIA con Maxwell y Pascal frente a AMD Polaris y Vega fue lo hizo que se vieran portátiles gaming con GPUs de NVIDIA y en cambio no se viesen de AMD con esas arquitecturas.
- Permite crear nuevas iteraciones mejoradas de una arquitectura para ser lanzadas posteriormente, las cuales serán más rápidas.
La forma más común de aumentar el rendimiento por vatio es a través de los nuevos nodos de fabricación, cada nuevo nodo resulta en una reducción del consumo que se traduce en una mayor velocidad de reloj bajo el mismo consumo u obtener un menor consumo con la misma velocidad de reloj.
Pero donde realmente se realizan los cambios, es a nivel de arquitectura, ya que los arquitectos realizan optimizaciones para que los nuevos diseños consuman menos energía a la hora de ejecutar las diferentes instrucciones, tanto a la hora de diseñar una CPU como una GPU.
Incluso dentro de una iteración menor de una arquitectura los ingenieros están siempre pensando nuevas formas para mejorar el rendimiento por vatio de las mismas, una vez terminada la primera versión de un diseño esto no significa que se olviden del mismo sino que durante toda su vida comercial va a recibir optimizaciones y mejoras con tal de rendir más sin aumentar el consumo energético y si es posible disminuirlo.
La importancia de mantener los datos cercanos a la GPU
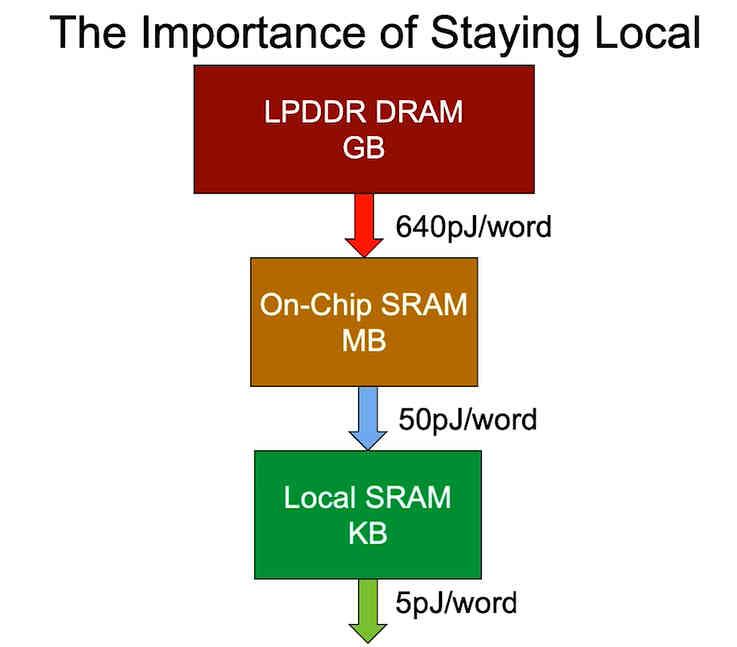
En una conferencia, Bill Dally, quien es en estos momentos el científico jefe de NVIDIA, dejo caer una anécdota en la cual comentaba que los ingenieros de NVIDIA se quedaban confundidos con una simple pregunta que él les hacía. ¿Habéis medido el consumo energético a la hora de mover los datos?
Pero, los datos no solo son procesados, sino que son también movidos por todo el procesador y dependiendo de donde se encuentren estos datos la energía consumida va a ser mayor o menor. Es por ello que en los diseños se procura que la mayor cantidad de instrucciones trabajen con datos dentro del procesador, la idea no es otra que reducir el consumo energético de estas operaciones.
Generación tras generación, las GPUs están cada vez más optimizadas para evitar en lo máximo posible realizar cálculos sobre la VRAM y las mejoras arquitecturales realizadas durante los últimos años han tenido ese objetivo: mantener lo más local posible los datos para reducir el consumo energético de las instrucciones.
big.LITTLE en las GPUs en el futuro para aumentar el rendimiento por vatio
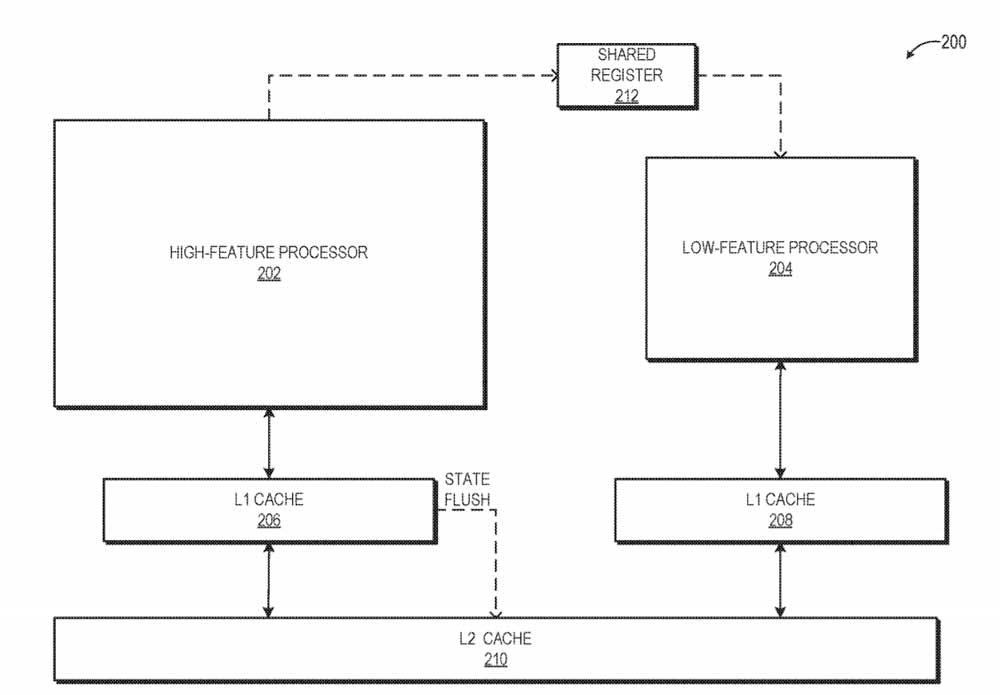
Aunque el termino big.LITTLE por el momento solo afecta a las CPUs, en el caso de las GPUs no hay duda que vamos a ver aparecer este concepto en arquitecturas a corto plazo, ya que al fin y al cabo las Compute Units no dejan de ser procesadores en si mismos. Más centrados en el paralelismo a nivel de hilos que de instrucciones, pero, el big.LITTLE se puede aplicar también en el caso de las GPUs.
¿En qué consiste? ,
- Las instrucciones más simples consumen mucho menos que las complejas.
- La velocidad de reloj de un procesador se ve tradicionalmente limitada por la velocidad de reloj de las instrucciones que más energía consumen.
- Las Compute Units harán uso de dos tipos de núcleos: uno para instrucciones muy simples que puedan llegar a mayores velocidades de reloj aprovechando el menor consumo, el otro para instrucciones más complejas, que alcanzarían velocidades de reloj menores.
La idea es aprovechar el mayor rendimiento por vatio que tendrían los núcleos más simples para realizar pequeños aceleraciones a la hora de renderizar la escena para que la suma del cómputo global entre ambos núcleos sea más alta, todo ello sin tener que aumentar el consumo energético global.
Rendimiento por vatio y unidades de Función Fija
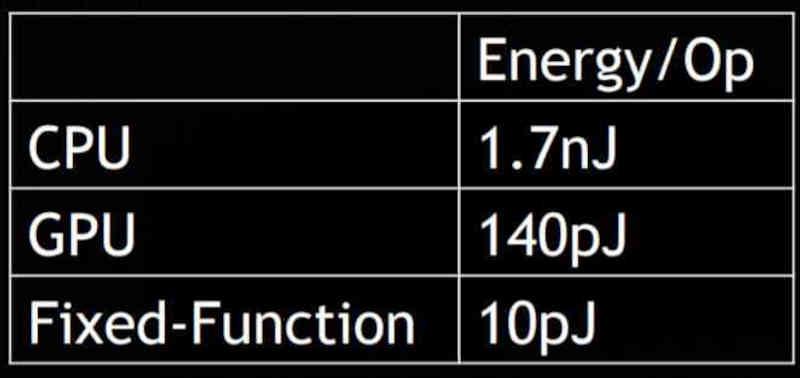
Las unidades microcableadas son unidades que no ejecutan un programa, sino que a partir de unos datos de entrada realizan siempre la misma sería de instrucciones.
Su utilidad es de cara a la ejecución de tareas repetitivas y recursivas. Un ejemplo de ello son las unidades de filtrado de texturas, cierto es que sería posible hacerlo con las unidades que ejecutan los shaders, pero esta serie de operaciones acabaría consumiendo varias órdenes de magnitud más.
La última unidad incluida en las GPUs es el RT Core o Ray Accelerator Unit, la cual libera a los shaders de realizar el calculo de la intersección de los rayos en el Ray Tracing, tarea que para realizarse con la misma velocidad requeriría un consumo energético enorme que incluso superaría lo que se puede permitir una GPU.
La memoria escogida afecta también al rendimiento por vatio
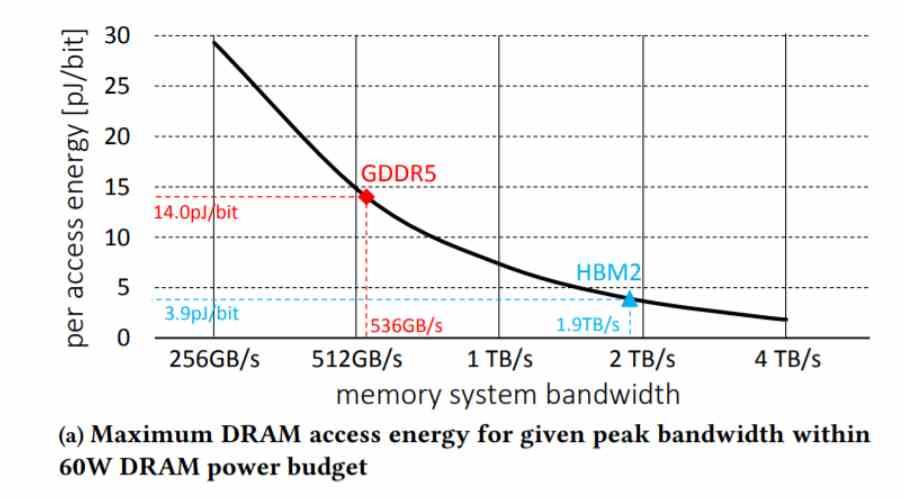
No todos los tipos de memoria tienen la misma eficiencia enegética, unas van a consumir más que otras y es una de las polémicas de los últimos años entre las memorias del tipo GDDR y las del tipo HBM.
- Las GDDR son muy baratas, pero a cambio consumen mucho más, dejando menos energía para la GPU, la cual alcanza velocidades de reloj mucho más bajas al tener menos energía para si.
- Las HBM ocupan muy poco espacio y consumen muy poco, pero son muy caras de implementar.
En el mercado doméstico las GDDR dominan desde hace años, pero en mercados donde el coste no es tan importante, las HBM dominan ya que su menor consumo energético a la hora de trasladar los datos las hace ideales para sacar el mayor rendimiento posible.
Se va a llegar al punto en que las memorias del tipo GDDR no van a poder alcanzar más, el problema es que la memoria con las ventajas de la HBM y que sea lo suficientemente barata aún no ha aparecido.
Fuente: hardzone.es/reportajes/que-es/rendimiento-vatio-gpu/