
Si ayer os comentábamos acerca de la configuración en lo que a la cantidad de GPCs, TPCs y SM tendría la mayor de las GPUs bajo la siguiente arquitectura de NVIDIA, según los rumores. Hoy os vamos a hablar del resto de las características que Lovelace podría tener, en concreto la mayor de las GPUs que formaran parte de las tarjetas gráficas de la eventual familia GeForce RTX 4000, en este caso del chip AD102, sucesor directo del GA102 de la RTX 3090.
Antes de nada, tened en cuenta que esta información solo son rumores y que a la espera que NVIDIA confirme información de esta arquitectura iremos comentando la información que vaya saliendo acerca de la siguiente arquitectura de NVIDIA, la cual no esperamos antes de 2022.
¿Qué nos podemos esperar de Lovelace?

Una de las cosas que nos sorprendió a muchos en las GeForce Ampere, RTX 3000, fue el hecho que NVIDIA duplico la cantidad de ALUs en FP32 dentro de cada SM, el truco para hacerlo es el hecho que a partir de las NVIDIA Turing fue hacer un cambio muy simple de explicar en las unidades SM.
En todas las GeForce hasta Pascal, los «núcleos» CUDA tenían dos tipos de ALUs en si interior, una de enteros y otra de coma flotante pero estás funcionaban de manera totalmente conmutada y compartiendo el camino de datos. Fue a partir de Volta y Turing, NVIDIA asigno dos caminos, uno para enteros y el otro para coma flotante, pero solo pudiendo activar 16 caminos, pero en Ampere hicieron que el camino de datos que comunicaba con las 16 ALUs de enteros lo hiciera también con otras 16 ALUs de coma flotante, que sumadas a las previamente existentes pasaron a contar un máximo de 128 ALUs en FP32 por SM, duplicando así la capacidad de cálculo en coma flotante máxima.
No sabemos si NVIDIA va a realizar un cambio del mismo tipo dentro de las características de Lovelace, pero si los rumores se hacen ciertos entonces la forma de aumentar el rendimiento por pare de NVIDIA no será aumentando la cantidad de ALUs en FP32 por SM o cualquier otra cosa, sino aumentar la cantidad de SMs en total.
Una ingente cantidad de núcleos CUDA en Lovelace

Si ya os comentamos el rumor de las características de Lovelace con una configuración de 12 GPC y 6 TPC por GPC, o dicho de otra manera, de los 12 GPC con 12 SM cada uno, ahora nos toca hablar de lo que esto significaría en el caso de que NVIDIA no haga cambios arquitecturales e ignorando otros elementos de la ecuación que harían más o menos posibles o creíbles estos rumores.
12 GPC *12 SM por GPC = 144 SM.
144 SM*128 ALUs en FP32 (núcleos CUDA) = 18432 «núcleos» CUDA/ALUs en FP32
En comparación la NVIDIA RTX 3090 tiene 82 SM con la misma configuración, 10496 «núcleos» CUDA, por lo que es un salto del 70% que unido a una eventual mejora en la velocidad de reloj podría significar un rendimiento más allá de los 60 TFLOPS de potencia de cálculo. Todo ello haciendo caso en exclusiva a la información de los rumores e ignorando otros factores.
Las características de Lovelace necesitan cambios más profundos

Normalmente NVIDIA asignaba una cantidad de GPCs equivalente al ancho de banda de la memoria, normalmente asignaba 6 GPC en el caso de un bus de 384 bits, 5 GPC en el caso de uno de 320 bits, 4 GPC en el caso de un bus de 256 bits, etc. Pero, si los rumores acerca de NVIDIA Lovelace resultan ser ciertos entonces esta equivalencia entre la cache L2 y los GPC se romperá, habrán más GPC por particiones de cache L2 y el ancho de banda necesario será más alto.
Si hacemos una observación rápida veremos como del salto de NVIDIA Maxwell a NVIDIA Pascal la cantidad de GPC se mantuvo pero la cantidad de TPC por GPC se aumento en uno. De Pascal a Turing ocurrió lo mismo, pero con Ampere no aumentaron el ancho por GPC sino que pasaron de 7 a 6 GPC.
Si las características de Lovelace son ciertas entonces el cambio que permitiría colocar una gran cantidad de GPCs estaría en la Cache L2 de la GPU, esta siempre comunica los diferentes GPC entre si, por lo que para poder escalar la cantidad de GPCs tiene que haber una forma de escalar la Cache L2, pero por el momento la desconocemos y solo podemos especular sobre ella.
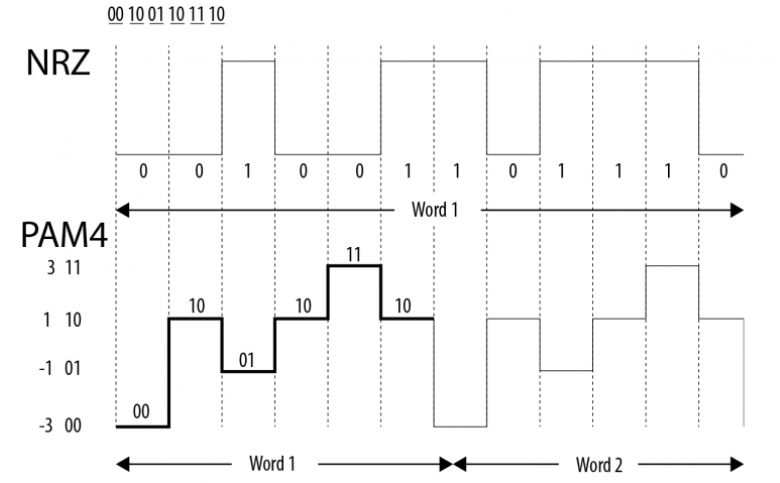
Una posibilidad es que al igual que se ha usado una interfaz PAM-4 para la comunicación con la memoria externa en el caso de la GDDR6 entonces NVIDIA haya decidido hacer lo mismo con la cache L2, aumentando su ancho de banda y permitiendo alimentar los 12 GPC que rodearían a la Cache L2.
Claro esta que esto tampoco resuelve que tal cantidad de unidades requieren también un gran ancho de banda para la VRAM, lo que nos hace creer que NVIDIA se guarda unos cuantos ases bajo la manga y que tardaremos un largo tiempo en conocerlos.
Fuente: hardzone.es/noticias/tarjetas-graficas/caracteristicas-lovelace/