
Los 5 nm van a suponer un cambio generacional importante en el caso de AMD, no solamente va a ser el despliegue de su arquitectura Zen 4, sino también el lanzamiento de la tercera generación de GPUs basadas en la arquitectura RDNA 3. De las cuales por el momento sabemos poco, pero lo suficiente para hacernos una idea aproximada de cuál será la apuesta de AMD para plantarle cara a la NVIDIA Lovelace.
La arquitectura RDNA 3 no aparecerá en el mercado hasta 2022 como muy pronto y puede que incluso tengamos que esperar a 2023, pero creemos que es buena idea hacerle un repaso de lo que sabemos que nos podemos encontrar en la siguiente generación de las AMD Radeon.
Cambios internos en la arquitectura RDNA 3

Los cambios que el Radeon Technology Group le van a hacer a la arquitectura interna de la tercera generación de sus GPU RDNA van a ser mucho más profundos que el salto de RDNA a RDNA 2, es por ello que hemos pensado que es importante recopilar la información a través de canales oficiales y extraoficiales acerca de las GPU que le plantarán cara a las NVIDIA Lovelace, contra las que competirá.
La mayoría de los cambios que veréis a continuación son obvios con la evolución de la tecnología, otros son para recortar la ventaja de NVIDIA en ciertos ámbitos y otros los sabemos por patentes.
Mejoras en las Ray Acceleration Units de RDNA 3

Uno de los problemas que tiene la implementación de cara al Ray Tracing para RDNA 2 es el hecho que para recorrer el árbol BVH requiere el uso de las unidades SIMD en la que se ejecutan los shaders, lo que provoca que la potencia de las Compute Units se tenga que compartir entre la ejecución de los shaders y el recorrido de la estructura de datos.
Esto no ocurre con los RT Cores de NVIDIA, pero el origen de todo es que en la especificación mínima DirectX Ray Tracing no es necesario el hardware de función fija para el recorrido, es por ello que AMD no lo ha incluido en las Ray Acceleration Units de RDNA 2.
Por lo que es un cambio que si o si va a incorporar AMD, pese a que su apuesta sea distinta en la actualidad que la de NVIDIA, pero la mayor cantidad de juegos diseñados para sacar provecho del planteamiento de NVIDIA obliga a AMD a adoptarlo.
Tensor Cores en RDNA 3 para DirectML
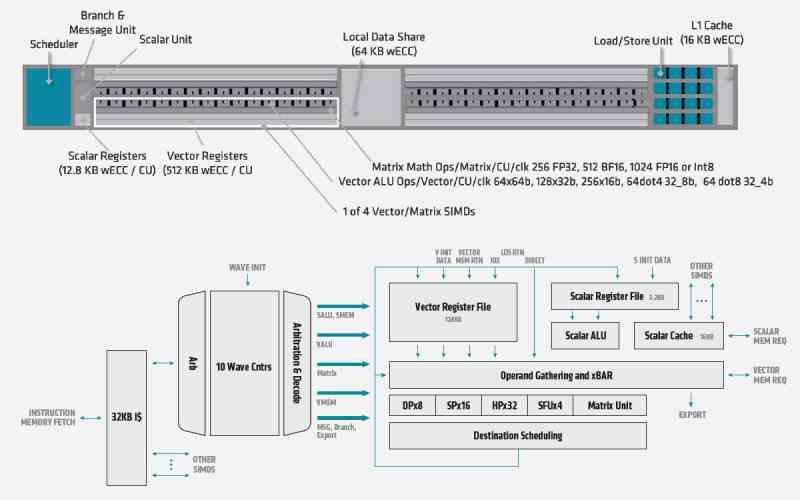
Una de las cosas que AMD ha añadido en la arquitectura CDNA son el equivalente a los Tensor Cores de NVIDIA, es decir, ALUs en forma de arrays sistólicos para acelerar la ejecución de ciertos algoritmos basados en la inteligencia artificial.
Esto ha sido una desventaja para AMD respecto a NVIDIA, ya que gracias a estas unidades se pueden implementar algoritmos como el DLSS que permiten renderizar a menos resolución internamente y por tanto ganar en la tasa de fotogramas por segundo en los juegos. Lo cual es una de las dos funciones principales para las que compramos una GPU, aparte de la calidad de los gráficos.
Los Tensor Cores de AMD se llaman Matrix Core, funcionan de la misma manera que los Tensor Core de AMD y su primera iteración tienen una tasa en coma flotante 3,5 veces superior en FP32 y 7 veces superior en FP16. Desconocemos si de cara a RDNA 3 vamos a ver mejorada esta unidad.
Cambios en el planificador de las Compute Units
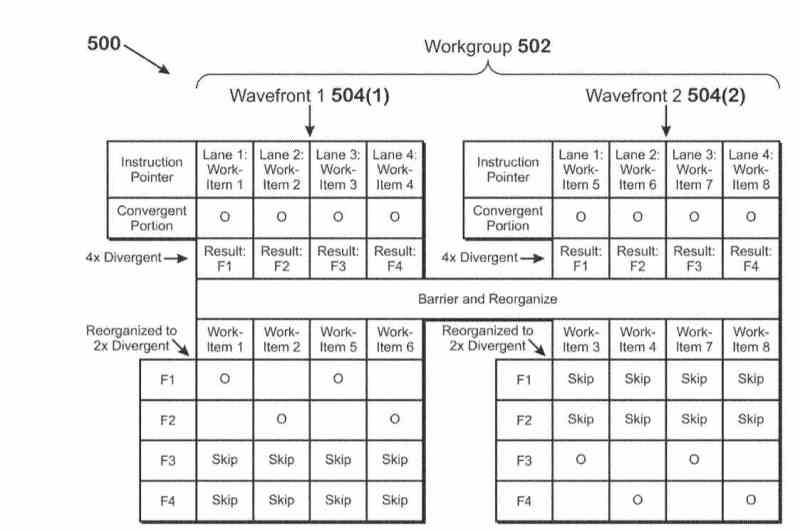
Las Compute Units a la hora de ejecutar los shaders lo que hacen es utilizar el método Round-Robin, el cual consiste en que se le da un tiempo de ejecución a cada instrucción, si esta no se resuelve en dicho tiempo por faltarle el dato entonces se pasa a la siguiente, todo ello para evitar que la Compute Unit se pare en la ejecución, pero, dicho tiempo de espera se traduce también en ciclos de reloj perdidos.
Es por ello que AMD hará un cambio en el planificador de la GPU, el cual se encargará de reordenar las lista de instrucciones a ejecutar de la Compute Unit, para reducir así aún más los tiempos muertos y aumentar el rendimiento de las Compute Units. Por lo que podemos decir que será la primera implementación de un sistema de ejecución fuera de orden en una GPU.
¿Doble de ALUs por compute unit en RDNA 3?
Un cambio que hizo NVIDIA en Turing es la ejecución concurrente, de tal manera que las unidades de enteros y coma flotante puedan trabajar en conjunto al mismo tiempo. En las RTX 3000 lo que hicieron fue añadir 16 ALUs en FP32 que funcionan de manera conmutada con las 16 ALUs de enteros, de tal manera que ahora pueden ejecutar hasta 32 instrucciones simultáneas por sub-core y hasta 128 por unidad SIMD.
El cambio de NVIDIA en los núcleos de sus RTX 3000 duplica la potencia en coma flotante sin tener que duplicar el resto de elementos que acompañan al SM, lo cual es una enorme ventaja para NVIDIA en los algoritmos de computación de propósito general de los que se beneficia el Ray Tracing.
Dado que cada vez habrá más juegos que harán uso del Ray Tracing, está claro que AMD tendrá que recortar esta ventaja de NVIDIA de alguna manera, pero por el momento no sabemos cómo lo van a hacer, con tal de recortar la enorme distancia en TFLOPS con la compañía de Jensen.
GPU por chiplets en la gama alta
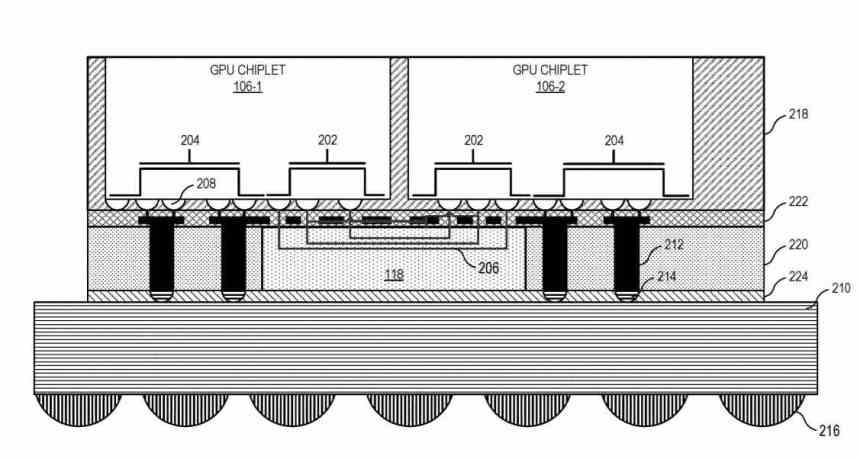
Sabemos que AMD lanzada una GPU dual en forma de chiplet en la gama alta de RDNA 3, pero esto no significa que veamos chiplets en la gama media y baja, donde se espera que sigamos teniendo chips monolíticos.
En todo caso si los rumores de NVIDIA son ciertos en cuanto a la enorme cantidad de SM en la versión más alta de su NVIDIA Lovelace, entonces la conclusión a la que llegamos es que AMD quiere repetir el mismo ejercicio que hizo con sus CPU Ryzen a partir de Zen 2, ya que a partir de ciertos tamaños la cantidad de chips buenos por oblea disminuye.
Hemos de tener en cuenta además que AMD ha incorporado la Infinity Cache en sus GPU a partir de RDNA 2, lo que lleva a que haya una mayor cantidad de espacio ocupado por la misma. Dicha caché va a convertirse en la caché L3 en el diseño basado en chiplets y es muy importante para la intercomunicación entre ellos.
¿Memoria GDDR6X como VRAM?
Pese a que la GDDR6 es una memoria con un excelente rendimiento, tiene el problema que su alta velocidad de reloj hace que las transferencias tengan un coste energético muy alto, de ahí el desarrollo de la GDDR6X que están utilizando ahora las tarjetas gráficas RTX 3000 de NVIDIA.
Realmente no sabemos si AMD va a utilizar este tipo de memorias, pero teniendo en cuenta que el consumo se comparte entre la VRAM y la GPU misma en un juego de suma cero. Entonces es muy probable que con tal de asignarle más energía a la GPU en AMD opten por la GDDR6X e incluso puede ser que veamos una generación de GPUs basada en RDNA 2 con dicha VRAM.
En todo caso, no sabemos cómo evolucionará la GDDR6, ya que en 2022 habrá disponibles nuevos nodos de fabricación de memoria que permitirán mayores velocidades y menor consumo, pero no olvidemos que a igualdad de ancho de banda la GDDR6X consume mucho menos y es por ello que pensamos que AMD también la adoptará.
Fuente: RDNA 3: ¿qué sabemos de la siguiente arquitectura de GPUs de AMD? (hardzone.es)